
(TIL) Day 12 TIL (20230221) – 데이터 전처리, 시각화, dplyr
1. 산술 연산자
– ^: 제곱 연산자
– %%: 나머지 연산자
– %/%: 몫 연산자
2. 논리 연산자
– R에서는 논리 값을 벡터화하여 논리 연산에 적용할 수 있습니다.
– &: AND, 벡터의 경우 각 요소를 개별적으로 연결하여 모든 결과 출력
&&: 벡터의 경우 첫 번째 요소 사이의 연산 결과를 반환합니다.
– | : OR, 벡터의 경우 각 요소를 개별적으로 연결하여 모든 결과 출력
|| : 벡터의 경우 첫 번째 요소 간의 연산 결과를 반환
3. 산술 함수
– prod(vector): 입력 벡터의 곱셈 값 출력
– Factorial(s): 1부터 입력값까지의 계승값 출력
– abs(벡터): 입력값의 절대값을 반환
– 범위(벡터): 입력 벡터의 최소값과 최대값을 반환
– var(vector)/sd(vector): 입력 벡터의 분산/표준편차를 반환
– Quantile(Vector): 0%에서 100%까지의 모든 4분위수 값을 반환합니다.
4. 문자열 관련 함수
– paste(string1, string2, …) : 값을 하나의 문자열로 합치는 함수
벡터 값을 개별적으로 인식하여 함께 반환
예) paste(c(1,2,3), c(‘숫자’, ‘숫자’, ‘숫자’)) -> c(‘숫자 1’, ‘숫자 2’, ‘숫자 3’)
– rep(vector, n): 벡터를 반복하여 길이 n의 벡터를 생성합니다.
먼저 each = n 옵션을 지정하여 각 요소를 반복하는 형태로 사용할 수도 있습니다.
5. 조건
5.1 만약
if (조건식){
실행문1
}else if{
실행문2
}
# 삼항연산자를 이용한 간단한 조건문 작성
ifelse(조건식, '참'인 경우 실행문, '거짓'인 경우 실행문)
5.2 스위치
switch(입력 값, 비교값1=실행문1, 비교값2=실행문2, … , 기본 실행문)– 입력값과 비교값이 같을 경우 해당 실행문을 실행
– 입력 값은 크기 1의 벡터여야 합니다. B. 간단한 문자열.
– 입력값과 일치하는 비교값이 없을 경우 기본 실행문을 실행한다.
– 비교값은 문자열 형식만 가능
5.3 어느
which(조건문)– 입력 벡터 내에서 조건과 일치하는 값의 인덱스(위치)를 반환
– vector(which(조건))를 사용하여 조건을 만족하는 해당 값을 추출할 수 있습니다.
6. 루프
# 1. for 반복문
for( 변수 in 데이터){
명령문
}
# 2. while 반복문
while(조건식){
조건이 참인 경우 수행할 명령문
}– 루프문으로 min 함수를 구현한 예
data <- c(32, 45, 21, 10, 43)
min <- Inf
for (i in data){
min <- ifelse(i <min, i, min)
}
print(min)
7. 벡터 위치 참조
– 해당 인덱스의 값만 벡터(인덱스)를 통해 참조할 수 있습니다.
– 인덱스에 음수 값을 입력하면 해당 인덱스에 있는 값만 제외된다.
8. 커스텀 함수
함수명 <- function(매개변수1, 매개변수2=초기 값, ...) {
실행문
return(리턴 값) #생략 가능
}
9. 데이터 가져오기
– scan(): 사용자로부터 직접 값을 수신하고 가져올 수 있으며, 숫자 형식만 지원
– scan(what = character()): 문자 타입 값 입력 가능
– read.table(filename, header=TRUE, sep=””, col.names=c(), na.string=””)
na.string: 데이터에 NA가 있을 때 표시되는 문자를 지정합니다.
– read.csv(파일 이름, 헤더=TRUE, col.names=c(), na.string=””)
– read_excel(파일명, 시트=NULL, 범위=NULL, col_names=TRUE, col_types=NULL, na=“”)
시트 = 시트 이름 지정
범위 = 데이터가 로드되는 행과 열의 위치 지정(R3C1: 3row 1col)
10. 데이터 내보내기
– write.table(데이터프레임 변수, 저장할 파일명, row.name=TRUE, quote = TRUE, sep=“ ”)
row.name: 행 번호 추가 여부 선택
견적: 문자와 같은 데이터에 “적용”할지 여부를 선택합니다.
– write.csv (데이터프레임 변수, 저장할 파일명, row.name=TRUE, quote = TRUE, nrows = n)
– write_xlsx(데이터프레임 변수, 경로 = 저장할 파일명)
11. 데이터 확인
– dim: 데이터의 차원을 확인합니다.
– length: 데이터의 길이 확인 / nrows(data): 데이터 프레임의 행 길이 반환
전체 데이터를 삽입할 때 열/행 길이를 알고 싶다면 data$column 형식으로 입력하면 됩니다.
– str(data): 클래스, 크기 및 미리보기 값을 제공합니다.
– 이름: 데이터 열 표시
– 보기(데이터): RStudio 뷰어 창에서 데이터 확인
– table(data$column): 각 데이터 값이 벡터에 몇 번 존재하는지 확인
12. 그래픽 표현
– 산점도: plot(x,y, type=’p’, main=NULL, xlab=””, ylab=””, xlim=c(), ylim=c())
type = ‘p'(점), ‘l'(선), ‘b'(점&선)
pch = 점의 모양(숫자 1~25, 문자로 지정 가능)
main = 그래픽 제목
– x축을 지정하지 않으면 0부터 연속으로 그려집니다.
– 파이차트: 파이(data, label = “”, init.angle = 0, radius = 1)
int.angle: 기준선 각도
반경: 원의 크기를 조정합니다.
테이블 개체를 삽입할 때 캡션이 자체적으로 추가됩니다.
– 히스토그램: hist(data, break = 10, frep = T)
나누기: 범주 수를 입력합니다.
frep = T(개수) 또는 F(속도)
– Boxplot: boxplot(data, boxwex = 상자의 폭)
데이터에 data.frame 형식을 사용하면 각 열에 대해 boxplot이 그려집니다.
plot()을 사용하여 그래프를 그린 다음 그 위에 lines()를 그려 한 그래프가 다른 그래프 위에 오도록 할 수 있습니다.
– 범례: Legend(“오른쪽 상단”(위치), legend=c(“label1”, “label2”), fill=c(“color1”, “color2”))
12.1 여러 그래픽으로 분할
– par(mfrow = c(분할 행 수, 분할 열 수))
행수 * 열수로 화면에 그래프를 그릴 수 있습니다.
## 화면 분할해서 그리기
par(mfrow = c(1, 2))
hist(data$Temp, breaks = 15)
hist(data$Temp, breaks = 20)
13.dplyr
– rename(데이터, 변경 후 컬럼명 1 = 기존 컬럼명 1, 변경 후 컬럼명 2 = 기존 컬럼명 2, … ) : 특정 컬럼의 이름을 변경
– array(data, desc(컬럼명), 컬럼명): 특정 컬럼의 값을 기준으로 데이터를 정렬(내림차순은 desc)
– unique(data,columnname): 데이터에서 특정 컬럼의 중복 값을 제거
– select(dataframe, columnname 1, columnname 2, …): 특정 컬럼을 순서대로 추출
파이프라인 사용 시: df %>% select(column1, column2)
– 필터(데이터프레임, 조건식)
파이프라인 사용: df %>% filter(수학 > 60 & 영어 < 80)
– mutate(to create dataframe,columnname1=formula1,…): 기존 컬럼 값으로 새로운 컬럼 생성
파이프라인 사용 시: df %>% mutate(평균 = (수학 + 과학 + 영어)/3)
– group_by + summarise: 특정 컬럼으로 그룹핑하여 계산 수행
파이프라인 사용: %>% group_by(id) %>% summarise(mathAvg = mean(math)) 확인
– count(df, columnname, sorting = T): 열에 있는 항목 수를 세어 반환합니다.
* select 와 apply pull() 으로 추출한 결과에 연산을 적용하고 싶다면 값을 벡터화해서 연산을 적용하면 됩니다.
14. 데이터 전처리 및 시각화 실습
14.1 문제)
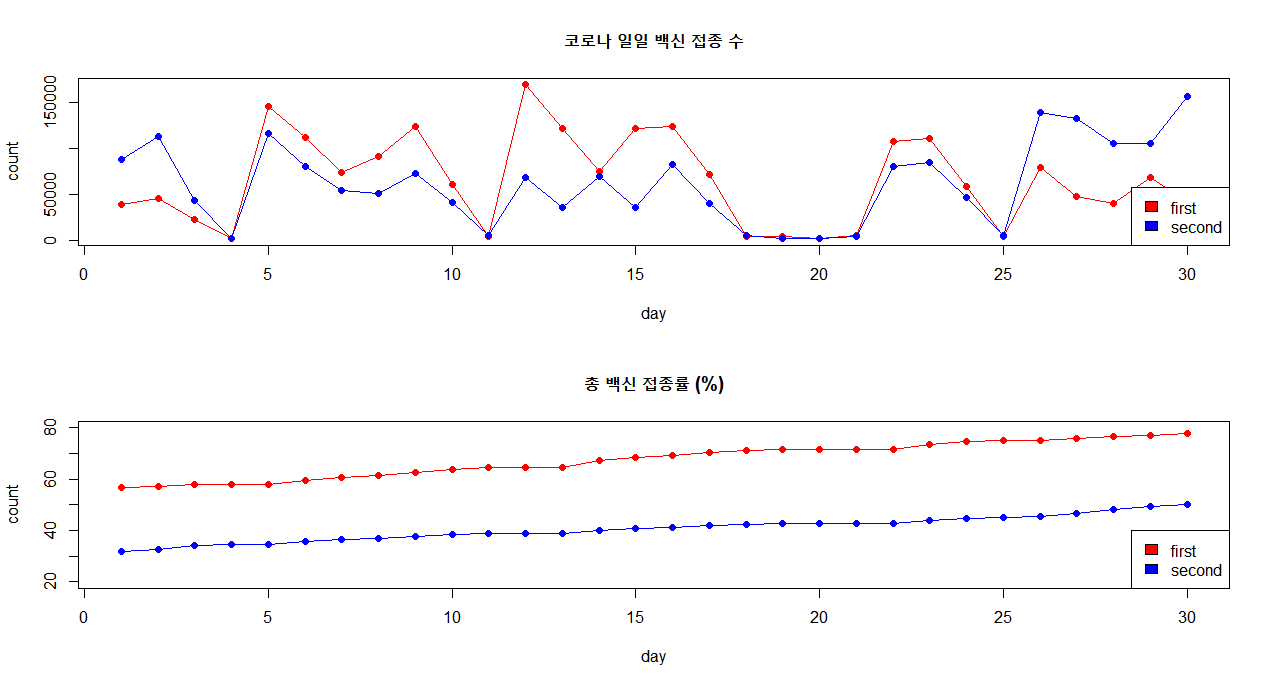
코로나 2021.09.01부터 2021.09.30일까지 집계된 접종 데이터에서 “1차 접종”과 “2차 접종” 데이터를 차트에 그립니다. 또한 “1. 접종률’과 ‘2. 접종률’을 그래프로 나타내었다.
# 데이터 불러오기
covid = read.csv('covid19.csv')
names(covid)
# 9월 데이터를 확인하여 추출
# 순서가 반대로 되어있어 이를 반영하여 원래 순서대로 불러옴
covid_1 = covid(c(64:35), c(3, 6)) # 접종자 데이터
covid_2 = covid(c(64:35), c(5, 8)) # 접종률 데이터
# 칼럼명 변경
names(covid_1) = c('first', 'second')
names(covid_2) = c('first_rate', 'second_rate')
# 그래프 그리기
par(mfrow = c(2, 1))
plot(1:length(covid_1$first), covid_1$first, pch = 19, type="o", main = '코로나 일일 백신 접종 수', col="red", xlab = 'day', 'ylab' = 'count')
lines(covid_1$second, pch = 19, type="o", col="blue")
legend('bottomright', legend = c('first', 'second'), fill = c('red', 'blue'))
plot(1:length(covid_2$first_rate), covid_2$first_rate, pch = 19, type="o", main = '총 백신 접종률 (%)', col="red", ylim = c(20, 80), xlab = 'day', 'ylab' = 'count')
lines(covid_2$second_rate, pch = 19, type="o", col="blue")
legend('bottomright', legend = c('first', 'second'), fill = c('red', 'blue'))
14.2 문제)
1. 대륙별 평균 GDP를 구하십시오.
2. Americas 데이터 프레임을 가져오고 총 행 수를 확인합니다.
3. 미국에서 인구가 3천만 명 이상인 데이터 프레임을 얻고 데이터 프레임에서 각 국가 열의 행 수를 찾습니다.
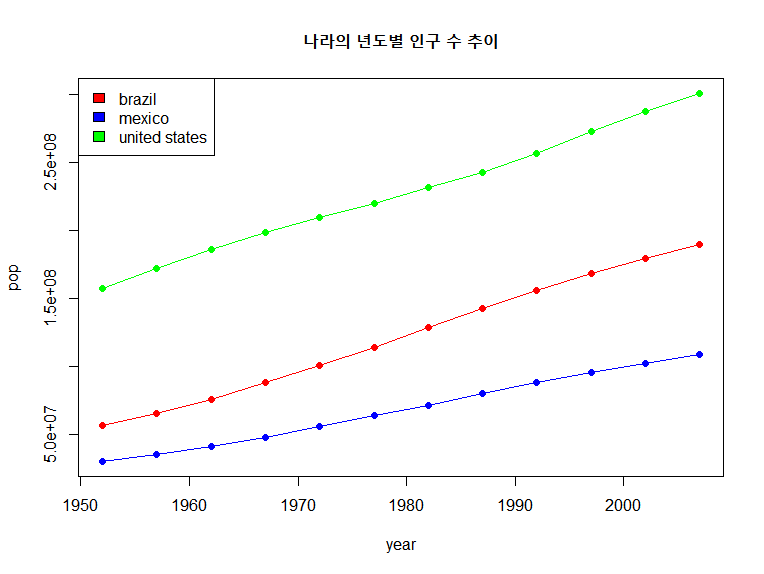
4. 브라질, 멕시코, 미국의 연도별 인구 도표를 그립니다.
## 대륙별 평균 GDP
gapminder %>% group_by(continent) %>% summarise(mean_gdpPercap = mean(gdpPercap))
## 아메리카 대륙에 대한 데이터 프레임을 구하고, 총 몇 개의 행이 있는지 확인
gapminder %>% filter(continent == 'Americas') %>% nrow()
## 아메리카 대륙에서 인구가 3천만 이상인 데이터 프레임을 구하고,
## 해당 데이터 프레임의 country 컬럼별 행 개수를 구하기
gapminder %>% filter(continent == 'Americas' & pop >= 30000000) %>% count(country, sort = T)
## Brazil, Mexico, United States의 년도 별 인구수를 한 그래프에 그리기
brazil <- gapminder %>% filter(country == 'Brazil') %>% select(year, pop)
mexico <- gapminder %>% filter(country == 'Mexico') %>% select(year, pop)
us <- gapminder %>% filter(country == 'United States') %>% select(year,pop)
min_y = min(c(brazil$pop, mexico$pop, us$pop))
max_y = max(c(brazil$pop, mexico$pop, us$pop))
plot(brazil$year, brazil$pop, type="o", pch = 19, ylim = c(min_y, max_y),
xlab = 'year', ylab = 'pop', col="red", main = '나라의 년도별 인구 수 추이')
lines(brazil$year, mexico$pop, type="o", pch = 19, col="blue")
lines(brazil$year, us$pop, type="o", pch = 19, col="green")
legend('topleft', legend = c('brazil', 'mexico', 'united states'),
fill = c('red', 'blue', 'green'))
인상 및 요약
어제에 이어 오늘은 R에 대해 진지하게 알아보는 시간을 가졌습니다. 저는 점차 전체 문법의 구조를 기억했지만 많은 세부 사항을 잊어버렸기 때문에 연습하는 데 오랜 시간이 걸렸습니다. 하지만 운동을 많이 시켜주셔서 감각을 빨리 익히는데 도움이 되었습니다. 2~3년 전쯤에 R을 주로 사용하던 시절에 dplyr 패키지를 많이 사용했는데 Python으로 전환한 초기에는 dplyr 패키지의 편리함을 놓칠 때가 있었는데 지금은 Python이 더 편리한 언어가 되었습니다. 하하… 하지만 실습을 진행하면서 dplyr 패키지가 여전히 R에서 빠르고 효율적인 전처리를 위한 좋은 도구라는 것을 확실히 느꼈습니다. 내일은 ggplot패키지로 시각화 공부중이라 dplyr로 많이 연습해봐야겠어요!